Project 08: HGNN-ClothDyn Demo: A Learned Cloth Surrogate in Taichi
Project code: projects/08-hgnn-clothdyn__project-space
This project is best understood as a three-step pipeline:
- Without my model: a mass-spring cloth simulator produces the baseline rollout on a fixed
40x40mesh. - With my model: an HGNN checkpoint predicts the same cloth dynamics on that exact topology.
- Final Taichi demo: the rollout is carried into a polished GGUI presentation, while still preserving a raw research view of the real simulation mesh.
The important point is not just that the final render looks smoother. The important point is that a compact learned checkpoint can stand in for a more expensive physical process strongly enough to survive validation, side-by-side playback, and a real geometry-based presentation layer.
Without My Model vs With My Model
The comparison that matters here is not "rough render vs polished render." It is "physics baseline vs learned surrogate."
Both sequences use the same fixed cloth topology:
1600vertices on a40x40grid- fixed top corners
- identical face connectivity for the baseline and learned playback
|
Without My Model Mass-spring baseline sequence exported directly from the reference physics path. |
With My Model HGNN rollout generated from the retrained checkpoint on the same mesh and time window. |
The left side is the target physical process. The right side is the learned surrogate. What matters is that the HGNN is preserving enough sag, bend, and short-horizon motion to stay legible as cloth instead of collapsing into plausible-looking noise.
What Changed To Make The Demo Smoother
The original demo worked, but it exposed the weakest part of the stack too literally: a coarse 20x20 cloth rendered almost directly as triangles.
The smoother result here comes from two honest changes:
- Denser surrogate data: the cloth baseline and retraining path were regenerated on a
40x40mesh while preserving roughly the original cloth size and total mass. - Separated raw vs polished rendering:
researchstill shows the actual simulation mesh, whilepitchanddramaticuse a denser Catmull-Rom display surface driven by the same rollout for presentation only.
That is the right split for this project. The simulation got denser for real, and the final presentation layer got smoother without pretending the model is simulating an even higher-resolution cloth than it actually is.
What The Numbers Actually Say
This project is now strongest when framed as a short-to-mid horizon surrogate.
Over the early rollout window that powers the exported demo, the retrained checkpoint is much stronger than the earlier recovered model:
- 20-frame position RMSE:
0.0370 - 20-frame edge-length MAE:
0.00136 - Inference speed:
161.8 FPSon an RTX 3090 Ti - Peak GPU memory during benchmark:
70.8 MB - Model size: about
619Kparameters
That is strong enough to support the side-by-side comparison and a wider polished export window.
The full autoregressive rollout is still not perfect, but it is no longer falling apart immediately:
- 200-frame mean position RMSE:
0.4602 - 200-frame final position RMSE:
0.3568 - Frame 40 RMSE: about
0.34 - Frame 100 RMSE: about
0.68
So the final demo is still built around the part of the rollout where the surrogate is strongest, but that trustworthy region is meaningfully wider than before. That is a better and more useful result than the original 20x20 pipeline.
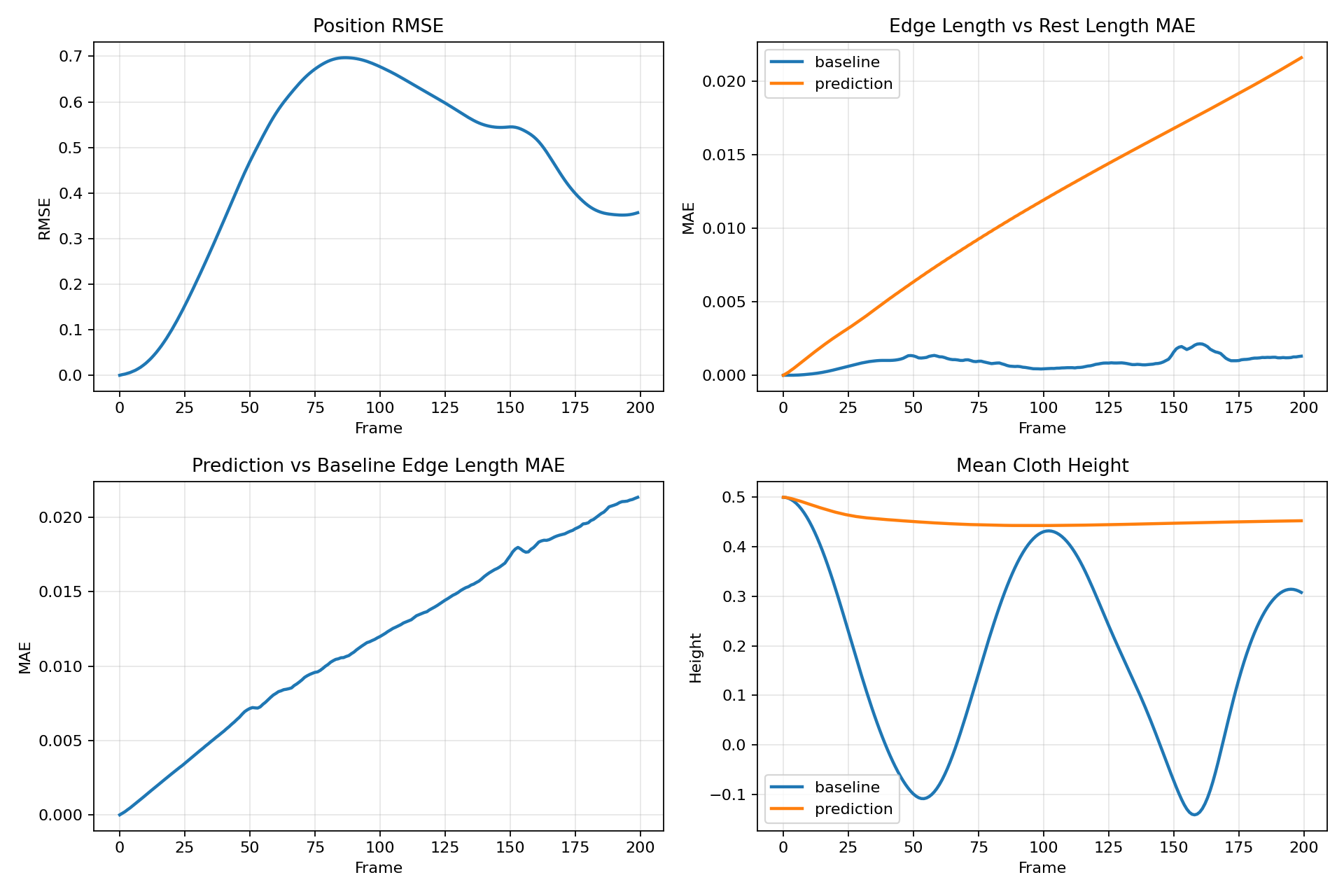
The plot above makes the tradeoff clear. Early and mid rollout frames now track well enough to sell the surrogate story cleanly. Long-horizon deviation still exists and should be treated as future work rather than hidden.
Why The HGNN Matters
Here is the strongest way to frame the project:
This work compresses a cloth dynamics process into a compact graph neural surrogate that can drive validation, playback, comparison, and polished rendering from one checkpoint.
That matters at several levels.
1. A cloth solve becomes a reusable learned object
Without the model, the useful output is a stored simulation sequence. With the HGNN, the useful output is a compact set of learned dynamics parameters on the fixed cloth graph.
That is the real representation shift in the project:
- without the model, cloth dynamics stay tied to the original simulation run
- with the model, the dynamics become something that can be benchmarked, replayed, exported, and repackaged downstream
2. One checkpoint drives the whole downstream stack
One .pt file now drives:
- rollout validation
- baseline vs learned comparison clips
- Taichi preset stills
- the final polished cloth demo
That is the practical workflow win. Once the checkpoint exists, the same learned object can feed research evaluation and presentation output without rebuilding the whole physics pipeline each time.
3. Simulation and presentation decouple
The expensive part of the workflow is generating or fitting the dynamics. The cheap part is reusing the learned result.
That matters for product and workflow reasons:
- a physics run can happen once
- the learned model can be benchmarked quickly afterward
- polished playback assets can be regenerated cheaply
- downstream presentation no longer depends on rerunning the original solver every time
The original implementation report put training at about 4 minutes 23 seconds on the 3090 Ti for the smaller mesh. The denser retrain here still completes in minutes on the same class of hardware, while the final checkpoint keeps inference near 162 FPS. That is the kind of ratio that makes surrogate workflows useful instead of merely academic.
4. The Taichi demo is a stress test, not just polish
Rendering the rollout as a fixed-topology mesh is useful because cloth is unforgiving. If the learned motion were incoherent, the mesh would expose that immediately through bad sag, unstable folds, or structurally implausible stretch.
So the final viewer is doing more than looking presentable. It is evidence that the learned rollout is coherent enough to survive a real geometry-based presentation layer.
Final Taichi Demo
The final presentation path loads the precomputed learned rollout, keeps the same cloth topology, and renders it as a clean Taichi GGUI mesh with deterministic offline export.
This matters because it closes the loop:
physics baseline -> learned HGNN rollout -> deterministic export -> polished Taichi presentation
That is the difference between "a model that predicts cloth numbers" and "a surrogate result that can actually be carried into a credible demo workflow."
Raw vs Polished
The final viewer is explicit about the difference between analysis and presentation:
- Research renders the actual
40x40simulation mesh with a wire overlay. - Pitch and Dramatic render a
118x118Catmull-Rom display surface driven by that same rollout.
That second path is a presentation-layer refinement, not a claim that the HGNN is simulating 118x118 cloth directly.
Taichi Presets
The viewer ships with three deliberate presets rather than one accidental look.
Research
|
Pitch
|
Dramatic
|
The default preset remains Pitch because it keeps the comparison readable on a laptop screen without drifting into the busier analytical look of research or the tighter, darker framing of dramatic.
Why It Matters
The value of this project is not just that the cloth animates convincingly for a few seconds.
The value is that it demonstrates a useful surrogate workflow:
- generate one denser trustworthy baseline
- train one compact checkpoint against that physics path
- benchmark it against the original rollout
- export comparison assets from the same learned object
- carry the result into a real presentation layer without inventing a separate rendering stack
That matters technically because it shows graph-based learned cloth dynamics can preserve structure well enough to remain legible under mesh rendering.
That matters for workflow because one checkpoint can drive research evaluation and polished communication output at the same time.
That matters for research signaling because the final demo is not just a pretty clip. It is evidence that the learned rollout is coherent enough to survive contact with a stricter viewer, cleaner framing, and direct comparison against the physical baseline.
If I reduce the whole post to one sentence, it is this:
The value is not that the cloth looks nicer in Taichi. The value is that one compact HGNN checkpoint can stand in for a cloth simulation strongly enough to benchmark, compare, export, and present.
What Would Make This More Realistic
The current result is strong enough to demo, but it is still not a fully convincing cloth surrogate in the sense that a graphics or simulation researcher would use that phrase in the strictest possible way.
The main realism limit is that the learned system is still operating on a relatively small regular cloth graph with a fairly simple synthetic physics process behind it. Even after moving from 20x20 to 40x40, the cloth is still much simpler than the kind of high-resolution cloth people are used to seeing in film-quality simulation, offline rendering, or even stronger interactive cloth demos.
Here is what would improve realism the most.
Realism has to improve across the whole stack
The main thing I would emphasize is that realism here is not one knob. It is a stack problem.
If I wanted this project to look and behave materially more realistic overall, I would think about it in five layers:
- Baseline physics: the reference process needs richer cloth behavior, not just more frames.
- Spatial resolution: the cloth graph needs more vertices so folds, sag, and curvature have room to exist.
- Training objective: the model needs to be rewarded for structural fidelity over longer windows, not just local next-step accuracy.
- Rollout policy: the inference path needs to stay stable when run autoregressively rather than only looking good under teacher-forced conditions.
- Presentation: the viewer should expose the cloth clearly without exaggerating artifacts or pretending the model is simulating a denser mesh than it really is.
If any one of those layers stays weak, the final result will still read as synthetic. Better shading does not fix weak motion. Better motion on a very coarse graph still looks faceted. A denser graph with unstable rollout still breaks under playback. The strongest improvement path is the one that lifts all of those layers in the right order.
1. Increase the physical resolution again
The jump from 20x20 to 40x40 helped materially because the simulation itself became smoother, not just the render.
The next realism jump would likely come from moving to something like:
64x6480x80- or even
100x100if memory and training time still stay practical
That would help in several ways:
- folds would resolve with more spatial detail
- sag and curvature would read more naturally
- triangle faceting would be reduced even before any presentation-layer smoothing
- the learned rollout would have to model richer local interactions instead of a very coarse cloth sheet
This is the single clearest path if the goal is "make it look more like real cloth" rather than merely "make the viewer prettier."
2. Make the baseline simulator physically richer
Right now the project is built on a useful but still fairly classical mass-spring cloth process. That is enough to train a credible surrogate, but it also puts a ceiling on what the learned model can inherit.
To make the motion more realistic overall, the baseline itself could be improved with:
- better bending behavior
- more carefully tuned damping
- clearer structural vs shear vs bend parameter separation
- better contact handling
- more realistic pinning and boundary conditions
- more varied cloth states, not just one canonical hanging sheet behavior
The surrogate can only learn the realism that exists in the training process. If the baseline has limited wrinkle richness or overly damped motion, the model will reproduce that limit.
3. Train on more diverse trajectories
At the moment, the project is strongest as a fixed-topology short-to-mid horizon surrogate on a narrow task family.
To make it feel more like a robust cloth model rather than a good demo for one scenario, the dataset should cover more variation in:
- initial conditions
- pin constraints
- gravity directions or strength
- cloth perturbations
- external forces
- stiffness and damping regimes
- rollout durations
This matters because realism is not only about surface smoothness. It is also about behavioral credibility across different states. A cloth model looks more believable when it reacts correctly under more than one carefully selected clip.
4. Improve long-horizon rollout stability
The current demo is built around the part of the rollout where the model is strongest. That is the correct honest presentation decision, but it is still a limitation.
For the system to feel more realistic in a deeper technical sense, the learned rollout should remain structurally believable further into the future. That means reducing drift, reducing accumulated phase error, and preserving cloth shape without the motion gradually becoming too soft, too wrong, or too detached from the physical target.
The most promising routes here would be:
- more aggressive autoregressive training
- curriculum on rollout length
- multi-step training losses instead of only local next-step emphasis
- explicit structural regularization during training
- losses on edge stretch, bending proxies, and velocity consistency
- better teacher-forcing to free-running transition schedules
If the model remains stable longer, the final demo can show a wider clip window without relying as heavily on careful clip selection.
5. Use better lighting and normals, but keep that secondary
Rendering still matters.
Even with better data, cloth can look fake if it is lit poorly. The current viewer already improved this with better framing and a smoother display surface, but realism could still increase with:
- more carefully tuned normals on the polished surface
- softer but directional key lighting
- a stronger sense of material response without becoming glossy or plastic
- subtler stripe or tone modulation
- slightly better floor interaction and shadow grounding
That said, this should remain a second-order improvement. Better shading on weak motion only creates prettier weakness. Better motion plus restrained shading is the correct order.
If I compress the realism roadmap to one line, it is this:
The path to more believable cloth is richer baseline physics, denser simulated geometry, stronger long-horizon learning, and only then more polished presentation.
What Would Improve The Project Overall
If I step back from realism alone and ask what would make this a stronger project overall, the answer is broader than just "denser cloth."
The other technical posts in this section each have one clear center of gravity: WavePINN is strongest on representation shift, and ClothGNN is strongest on speed regime. For this cloth project, the equivalent center of gravity should be: a learned surrogate that stays structurally believable enough to survive direct mesh rendering and side-by-side comparison.
That means the best improvements are the ones that strengthen not just the viewer, but the whole argument.
1. Make the evaluation more complete
The current metrics are good enough for the post, but the project would be stronger with a more complete evaluation suite.
Useful additions would include:
- explicit per-frame stretch and compression statistics
- bending or curvature surrogate metrics
- temporal smoothness metrics
- pinned-vertex consistency checks
- failure case galleries
- performance scaling as mesh resolution increases
That would make it easier to say not only that the rollout is close in RMSE, but also that it preserves the right kinds of cloth behavior.
2. Separate benchmark modes more clearly
The project now has several modes mixed into one story:
- research validation
- visual comparison
- polished presentation
That is good for a demo, but a stronger project structure would make those layers more explicit:
- a research benchmark path
- a reproducible export path
- a polished presentation path
The code has started moving in that direction already. Pushing that split further would improve maintainability and make the whole pipeline easier to explain and rerun.
3. Add ablations
This project would become much more convincing to a technical audience if it showed what actually matters.
For example:
20x20vs40x40- raw mesh render vs polished display mesh
- one-step training vs stronger autoregressive training
- with and without structural regularization
- different rollout windows
Ablations do two things at once:
- they make the writeup more defensible
- they help explain why the final demo looks the way it does
Right now the post tells a good story. Ablations would let it prove that story more rigorously.
4. Move from one strong clip to a small test suite of clips
The final export currently focuses on the strongest trustworthy window. That is the right move for a meeting, but the next improvement should be to support several curated clips:
- a canonical hero clip
- a stress clip
- a failure clip
- a raw-vs-polished clip
That would make the project more honest and also more reusable. People trust a system more when they can see where it works, where it bends, and where it breaks.
5. Improve reproducibility and packaging
The project is already much better than when it started, but it would benefit from a cleaner one-command story for:
- dataset generation
- training
- benchmark export
- Taichi artifact generation
- blog media sync
This matters because a good research demo is not only something that can be shown. It should also be something that can be rebuilt without archaeology.
6. Turn the post itself into a stronger technical artifact
The writeup can also carry more technical weight.
To make the page stronger as a research-style artifact rather than only a polished case study, I would add:
- one compact ablation figure showing
20x20vs40x40 - one failure-case comparison strip
- one short methodology block describing the normalization and rollout setup
- one explicit note on what is simulated directly versus what is presentation-layer smoothing
That would make the post more self-contained and more defensible for a technical reader landing on it cold.
If I Were Continuing This Project
If I had another serious pass to improve this project rather than just polish the current milestone, I would prioritize the work in this order.
Priority 1: better training target and longer stable rollouts
The first serious investment should go into making the learned rollout more trustworthy over longer windows.
That means:
- denser or richer baseline data
- better autoregressive training
- stronger structural losses
- explicit stability-focused validation
This is the highest-leverage improvement because it strengthens both the research result and the final demo.
Priority 2: higher-resolution simulation
If compute allows it, I would push beyond 40x40.
This is the most direct realism gain because it improves the underlying geometry and the learned target itself. It would also reduce the gap between the honest raw mode and the polished presentation mode.
Priority 3: more diverse cloth scenarios
Once the main surrogate is stable, I would broaden the dataset so the system is not just a good surrogate for one hanging-cloth setup.
That would make the project feel less like a tuned demo and more like a reusable learned cloth module.
Priority 4: presentation refinements
Only after the above would I spend more time on:
- richer material response
- more nuanced lighting
- stronger poster frames
- more polished preset styling
Those matter, but they are downstream of the dynamics.
Honest Current Limitations
A good technical post should say clearly what still is not solved.
The main current limitations are:
- the model is still best understood as a short-to-mid horizon surrogate rather than a fully stable long-horizon simulator
- the cloth topology is denser than before but still modest by high-end simulation standards
- the polished viewer uses a denser display surface, which improves presentation but does not mean the learned model itself is simulating that denser mesh
- the baseline physics is synthetic and intentionally simplified, so there is still a realism ceiling built into the source data
- the final export is curated around the part of the rollout where the model behaves best
None of those invalidate the result. They just define it correctly.
Why I Still Think The Project Is Worthwhile
Even with those limitations, I think the project is valuable because it crosses an important threshold.
It is no longer just:
- a training script
- a benchmark number
- or an animation that only looks acceptable in the exact environment where it was generated
It is now a compact learned cloth surrogate with:
- a denser baseline
- a recovered and improved training path
- explicit validation artifacts
- a raw analysis mode
- a polished Taichi presentation mode
- deterministic export
- and a publishable technical writeup
That combination matters. A lot of surrogate projects stop at "the numbers are decent" or "the render looks cool." This one is stronger because it now connects data generation, model fitting, rollout export, evaluation, and presentation into one coherent workflow.