Project 02: WavePINN-NIF Complex Media Demo: a verified acoustic reference and an honestly-failed neural surrogate
Project code: projects/02-WavePINN-NIF-ComplexMedia__project-space
The hero here is not the neural model. It is the verified finite-difference acoustic reference rendered through the Taichi viewer. The WavePINN-NIF surrogate is real, trained, and evaluated, but it fails the held-out tail of the clip. That makes this a baseline-hero project: verified acoustic propagation through a smooth heterogeneous medium, with an honest neural-surrogate ablation beside it.
The Core Representation Shift
The intended shift is from a discrete-grid finite-difference acoustic simulation to a callable continuous pair: u(x, y, t) for wave amplitude and c(x, y) for the medium. That representation would be useful if it generalized, because a trained field could be queried between frames, resampled at different render densities, and reused without replaying the solver. This rebuild verifies the acoustic reference and installs the evaluation infrastructure needed to test that claim, but the current surrogate does not pass those tests.
Without My Model vs With My Model
|
Without My Model Finite-difference reference snapshots. 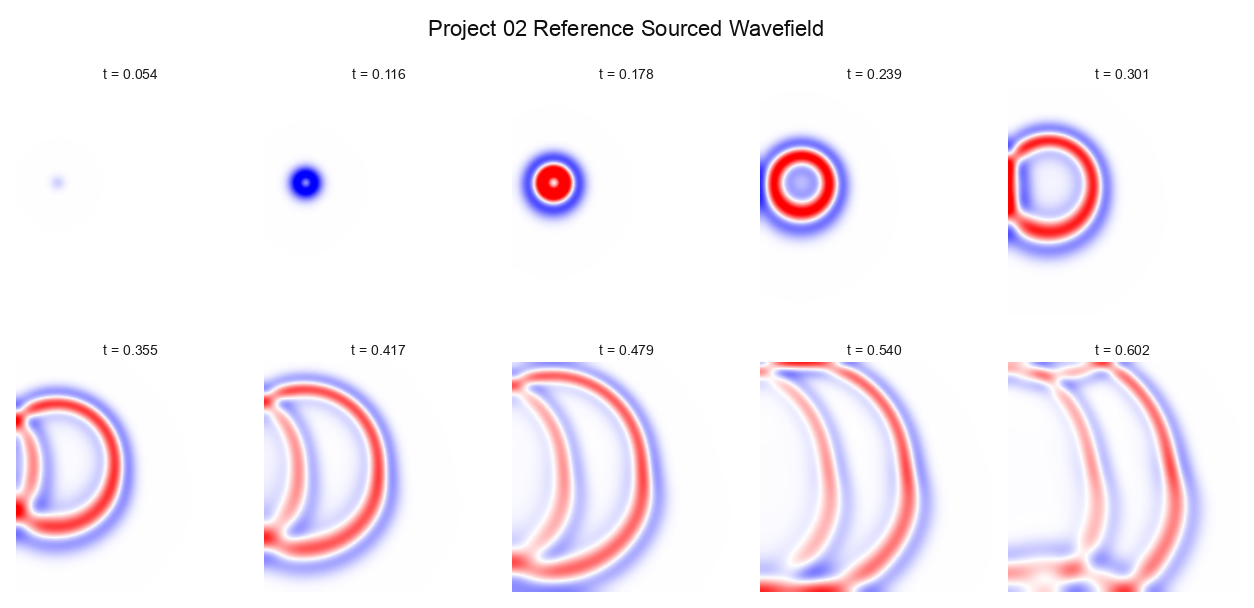
|
With My Model Learned surrogate snapshots over the same sequence. 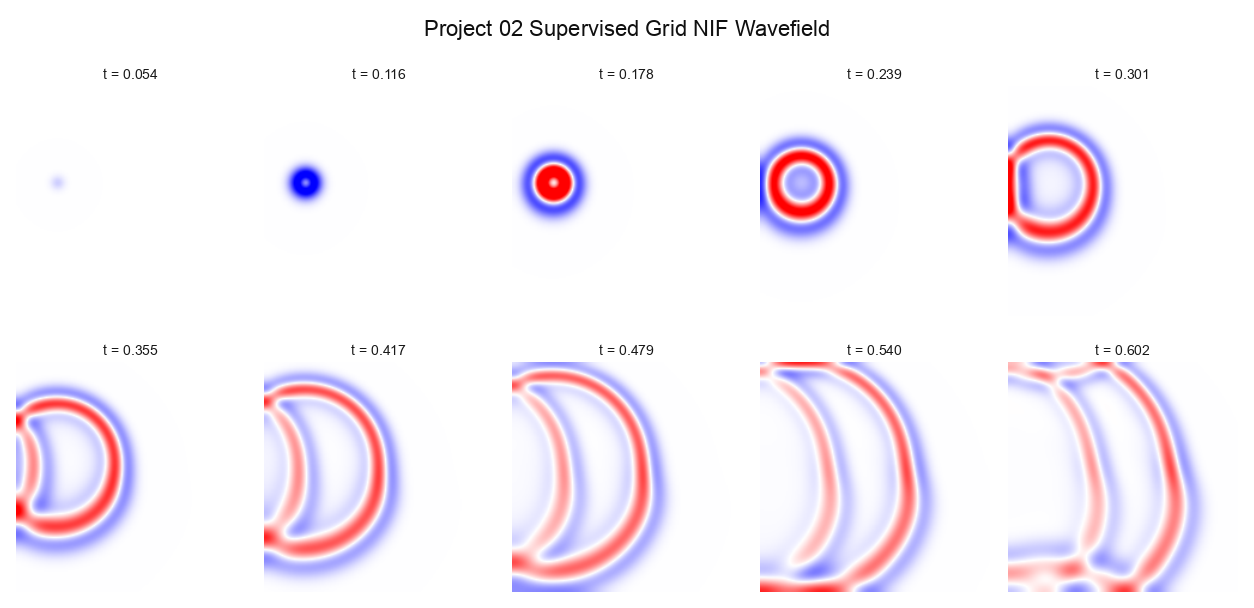
|
Left: the finite-difference reference. Right: the learned JAX/Haiku WavePINN-NIF surrogate. The model trains on frames 0..71; the held-out window is frames 72..95. The source event appears in both clips, but the learned field loses coherence through the held-out tail.
That split matters. The comparison is not asking whether the model can reproduce a visually plausible wave while it is still near the training window. It asks whether the continuous field remains a trustworthy surrogate after the supervised frames end. On this run, it does not.
What's Doing The Work
The supervision contract is load-bearing. The rebuilt trainer feeds real wavefield samples through a data loss, directly supervises the medium network, uses nonzero initial-condition targets from the reference, and includes the Ricker source term in the PDE residual. Without that contract, the training objective can reward a sourceless zero field or a model that fits only boundary conditions.
The reference preflight is load-bearing. The finite-difference reference now has to prove it contains a real wave before it becomes training data: max amplitude 0.595369, temporal motion variance 1.104404e-04, and 86 substantive frames. Without that check, a weak or over-damped reference can make a failed training run look numerically quiet.
The held-out evaluation protocol is load-bearing. The model is judged on a time split, off-lattice sampling, and held-out collocation residuals. Without those tests, the project would only know whether the model matched samples near the training grid. With them, the failure is findable: the learned field is distinct from the reference, but it does not generalize through frames 72..95.
What I Almost Published
The first version of this project produced numbers that looked better than a normal surrogate result. The reported NMSE was 0.0. The PSNR was capped at 120.0 dB. The energy ratio was 1.0. The medium correlation was 1.0. Every gate threshold passed, and the final metadata called the result a full WavePINN-NIF hero path.
Those numbers were not impressive. They were unfalsifiable.
The replacement training script that was supposed to repair the original JAX trainer did not train a network. Its core function copied the reference arrays into the object that later got serialized as a checkpoint:
wave_params = reference_wavefield.astype(np.float32).copy()
medium_params = reference_medium.astype(np.float32).copy()
The validation path then loaded those same arrays back out and compared them to the reference arrays they came from. The checkpoint contained keys like params.wavefield_grid and params.medium_grid, not Haiku or Torch weights. The validation wavefield was byte-identical to the reference wavefield. The medium prediction was byte-identical to the reference medium. A gate that only reads thresholded metrics will accept that, because the metrics cannot fail. The comparison is reference versus reference.
That is a different class of failure from an overfit model. An overfit network can still be interrogated: evaluate a new time, a new coordinate, or a new source setting, and the metric can expose the boundary of what it learned. The copied-array checkpoint had no such boundary. It was not a continuous field, not a PINN, and not a surrogate. It was a stored reference cache with model-shaped metadata.
There was a second problem underneath it: the archived finite-difference reference was nearly zero. Its max amplitude was 0.006549, and its temporal motion variance was 1.336328e-08. Even a real model trained against that field would not have demonstrated useful acoustic propagation.
The rebuild changed the evaluation structure before trusting any model output. It added a reference non-triviality preflight. It rejected byte-identical and near-identical learned arrays. It required the learned field to have nonzero motion and a plausible, non-exact energy ratio. It split training and evaluation by time, sampled 1000 off-lattice (x, y, t) points, and measured PDE residual on held-out collocation points. It also made the medium fit explicit: a real supervised MediaNIF can be reported, but not described as inverse recovery.
That is why the current numbers mean something. They are worse, but they could have failed, and did fail. Honesty here is a property of the evaluation pipeline, not the prose around it.
The Final Taichi Demo
Research
|
Pitch
|
Dramatic
|
The Taichi viewer samples the field on a fixed 192 x 192 grid and renders it as a heightfield with 36,864 vertices and 72,962 faces per single-subject frame. The topology is fixed across time. research exposes the grid more directly, while pitch and dramatic use the shared studio rig, tanh transfer, and a restrained positive/negative palette.
The hero mode is the FD reference because the learned surrogate fails Gate 5 on held-out evaluation. The comparison clip remains part of the post because it shows the model's actual behavior rather than hiding it behind the reference hero.
What The Numbers Actually Say
On held-out frames 72..95, the learned wavefield gets NMSE = 4.483927e-01 and PSNR = 23.589 dB. The trust-window fraction is 0.000 under the required rule that held-out frames must satisfy both NMSE <= 1e-3 and PSNR >= 30 dB. This is the main result: the learned field does not pass the surrogate gate.
The off-lattice test gives NMSE = 3.917936e-01, PSNR = 20.211 dB, and MAE = 1.261716e-02 over 1000 random (x, y, t) samples. This is the continuous-field test. A coordinate model should be useful between grid points and between saved frames; this one does not yet meet that bar.
The held-out PDE residual RMS is 1.693649e+01. That number is consistent with the field error: the model is not just missing a display metric, it is not satisfying the sourced acoustic equation well on held-out collocation points.
The medium network is much stronger numerically. MediaNIF gets NMSE = 5.665654e-08, correlation 0.999999, and off-lattice medium NMSE = 4.478484e-08. That is a real supervised network fit to c(x, y), but it is not inverse identification. The medium is prescribed and known during training.
Reference x-t slice
|
Learned x-t slice
|
Prescribed medium vs supervised MediaNIF fit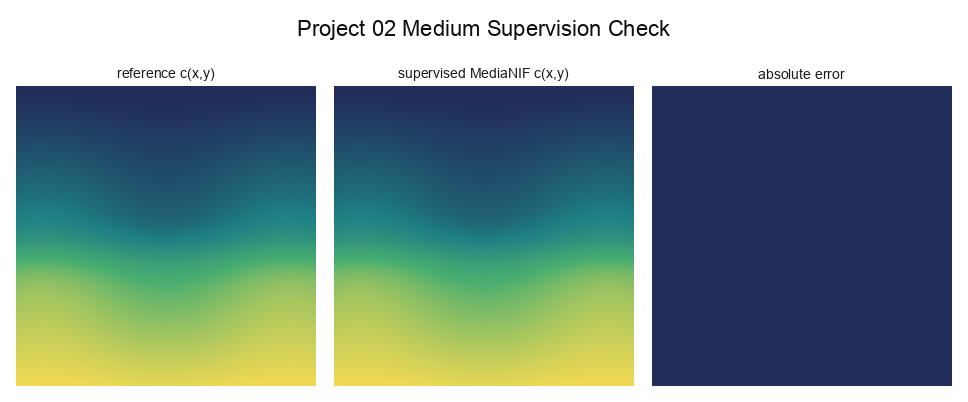
|
|
One blind spot remains: the split is time-only. The model has not been tested on a held-out source location, a new frequency, or a perturbed medium realization. The current failure characterizes time extrapolation inside one scenario, not full acoustic generalization.
Applications
For 3D short films / VFX / previs / shot pipelines
A passing version of this surrogate would be useful as a compact neural wave cache: one checkpoint queried at arbitrary times, sampled at render-specific grid density, and re-framed through the Taichi viewer without replaying the reference solver. It could support timing changes, intermediate-frame resampling, and resolution-independent look development for wave-like scalar-field shots.
This version cannot be used for that. The FD reference can be used as a rendered acoustic shot within its simulated time window and 192 x 192 grid. The learned surrogate cannot replace the solver, cannot support source edits, cannot handle new media, and cannot promise reliable behavior past the training window.
For technical experiments / research
The reusable part is the evaluation infrastructure. Project 02 now has identity-fit rejection, a reference non-triviality gate, a train/held-out time split, off-lattice field evaluation, held-out PDE residuals, and separate medium metrics. Those are directly reusable for future continuous-field PINN projects.
The contract repair is the research value here. It gives the next run a way to fail clearly: source forcing can be ablated, medium supervision can be removed, data loss can be reduced, and PDE-only training can be tested against a reference that is already known to contain real motion.
Honest Current Limitations
The learned wavefield does not pass the held-out gate. It fits the training window better than the tail, then loses coherence across frames 72..95.
The medium network is real and supervised, but the correlation of 0.999999 is against the same c(x, y) it was trained on. This is not a recovered medium from wave observations.
The clip displayed as the hero is the trustworthy one: the finite-difference reference. The learned model's clip is shown for comparison and is worse on the held-out tail.
What Would Make This More Realistic
[modeling] high leverage- Address the time-extrapolation failure directly. Either put stronger PDE residual pressure on collocation points in the held-out time range during training, or switch from a coordinate-fit MLP to a recurrent or state-space architecture with an explicit forward-integration bias.[data] high leverage- Add held-out source positions and held-out medium realizations. A time-only split cannot show whether the model has learned acoustic structure across scenarios.[presentation] medium leverage- Keep the display-only smoothing visible in metadata and add an error diagnostic strip beside the comparison. Spatial smoothing and per-preset height scale improve legibility, but visual legibility and physical legibility are different.[modeling] medium leverage- Revisit Fourier-feature bandwidth and encoder calibration. The current calibration may fit the smooth medium easily while under-resolving the moving wavefronts.
What Would Improve The Project Overall
The new evaluation infrastructure makes useful ablations possible: source forcing on versus off, medium supervision on versus off, data loss only, data plus PDE, data plus velocity, and PDE-heavy training against the same nonzero reference.
The project also needs a field-query CLI that loads the checkpoint and evaluates u(x, y, t) and c(x, y) at arbitrary points. That would make the continuous representation testable without opening the Taichi viewer or writing custom notebook code.
Packaging should pin the JAX/Haiku environment used on the 3090 Ti and expose the finite-difference reference generator as a reproducible script. The strongest future version of this project would make the reference, trainer, evaluator, and renderer separate entrypoints with separate artifacts.
The post itself should remain tied to gate evidence: reference verification, held-out metrics, off-lattice metrics, PDE residual, and medium supervision status. The writing should not be able to certify a claim the metrics cannot support.
If I Were Continuing This Project
[modeling] high leverage- Fix the time-extrapolation failure first. Rationale: the current bottleneck is structural; the coordinate MLP fits values inside the supervised time range and does not behave like a forward wave integrator outside it.[data] high leverage- Add held-out source positions and held-out medium realizations next. Rationale: once time extrapolation improves, the next question is whether the model learned one scenario or a reusable acoustic mapping.[presentation] medium leverage- Add a reference/learned/error strip to the post and metadata. Rationale: the viewer is visually clear, but error localization would make the failure easier to inspect at a glance.[modeling] medium leverage- Recalibrate the Fourier features against wavefront frequency, not only medium smoothness. Rationale: if the encoder spends capacity on the easy smooth medium, it may leave the moving wavefront under-modeled.